什么是DOM
平时我们写的html标签本质上就是一堆字符串,html文件组成的字节流实际上是无法被浏览器渲染引擎理解的。为了让渲染引擎能够解析这些字符串,并且让JavaScript能够动态操纵网页元素而不是直接操作一堆字符串,于是就有了DOM这个概念。DOM让html文档能够有结构化的表述。在渲染引擎中,DOM主要有三个层面的作用:
- 从页面的角度来看,
DOM就是生成页面的基本数据结构 - 从
JavaScript的角度来看,DOM提供了接口让JavaScript有能力操作页面的元素,改变页面的结构、样式和内容 - 从安全的角度来看,
DOM提供了一个安全的容器,让一些不安全的内容直接在DOM解析的阶段就被排除了
DOM树的生成
上面我们提到渲染引擎无法直接识别html文档字节流,所以在渲染引擎渲染页面之前html文档会被交给HTML解析器,让它先把html文档转换为DOM结构,再供渲染引擎使用。
HTML解析器在解析html文档时是一边加载一边解析的,也就是说html文档加载了多少内容它就解析多少内容,而不是等html文档全部加载完才开始解析内容的。这就像编译型语言和解释型语言,显然HTML解析器的工作模式是同解释型语言一样的。
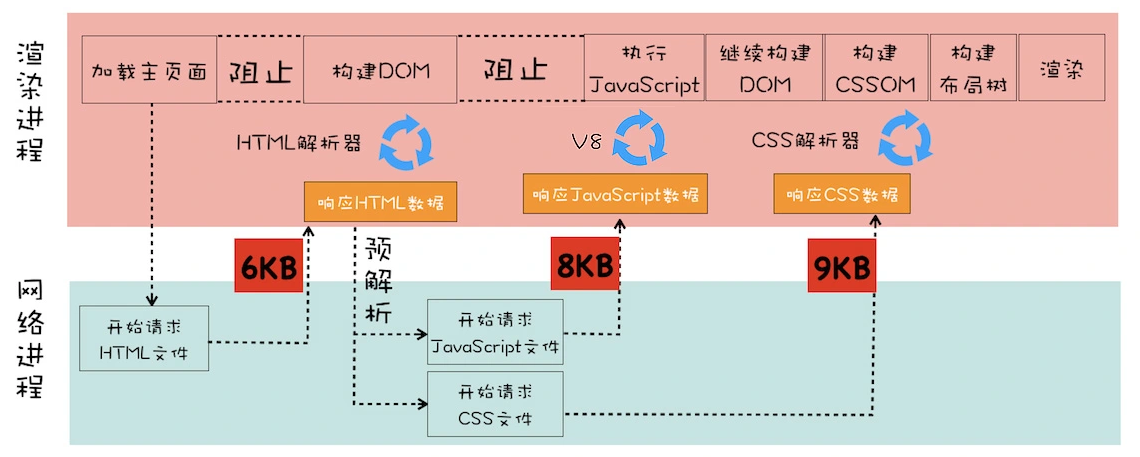
在加载页面时,浏览器网络进程接收到响应头后会根据响应头中content-type字段来判断文件类型,接着启动相应进程去处理接收到的文件。如html文件的content-type字段是text/html,浏览器就会启动一个渲染进程去处理它。渲染进程启动完,网络进程和渲染进程之间会建立一个共享数据的管道,网络进程接收到多少内容就同时往管道里添加多少内容,而渲染进程就一直读取管道里的数据进行解析渲染。
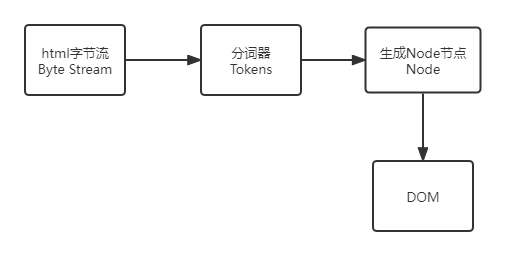
DOM生成
将html字节流转换为DOM的过程大致分为三个阶段:
- 通过分词器将字节流转换为
Token,这一点类似JavaScript解析 - 生成
Node节点 - 生成
DOM
在分词器生成Token阶段,字节流一般会被转换成两种Token:Tag Token和文本 Token。经过分词器处理后Tag Token会被划分成StartTag 和EndTag。如:
<html>
<body>
<div>
Asuhe
</div>
</body>
</html>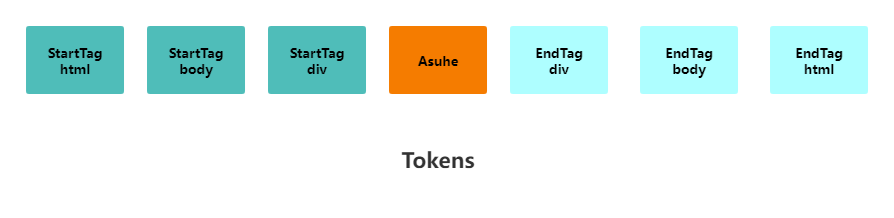
后续的生成Node节点和DOM是同步进行的,将Token变成Node节点再将DOM插入DOM树中,到这里文档的DOM树就基本生成完毕了。
利用上面生成的Tokens,HTML解析器维护了一个Token栈结构。利用栈来进行标签匹配完成TagT Token的闭合,其和括号匹配是一样的。以上面的代码为例,HTML解析器首先会将html、body、div的StartTag入栈,文本Token会直接拿去生成DOM加入DOM树,在遇到EndTag就弹出栈顶的StartTag,将其插入DOM树。HTML解析器开始工作时,会默认创建一个根为document的空DOM结构,同时将一个StartTag document的Token压入栈底,后面再装入分词器分类出的token,文本Token会被插入在其上一个Tag Token的后面作为其子节点
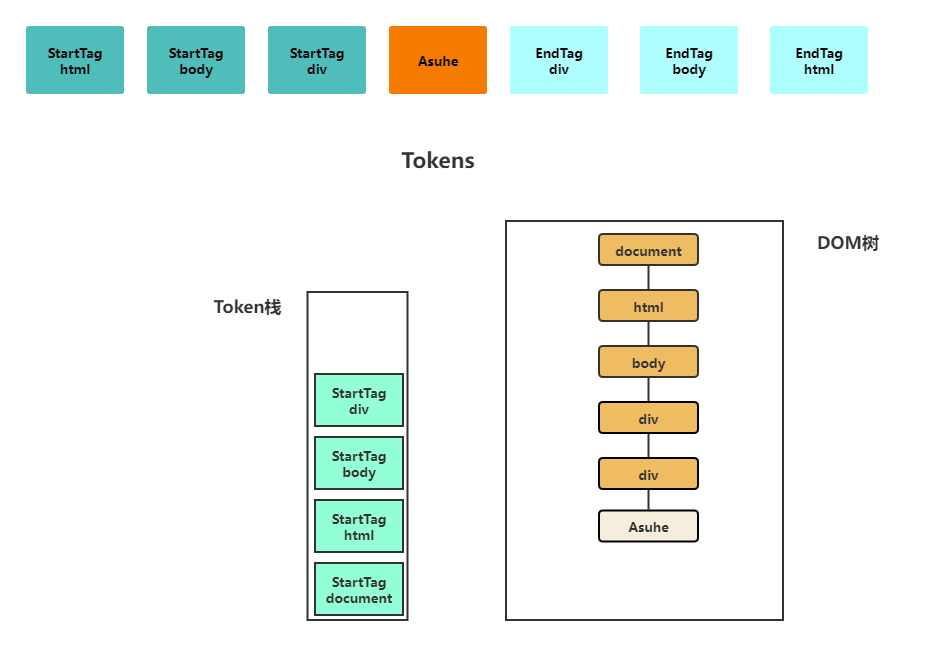
每当Token栈里出栈一个元素的时候DOM树就会生成相应节点并插入,所以最后文档渲染完毕时Token栈为空。
分词器解析出Token后,渲染引擎的XSSAuditor模块会启动,检查词法安全。例如是否引用了外部脚本、是否符合CSP规范、是否跨域请求等等,若出现不规范的内容XSSAuditor会对该脚本或者下载任务进行拦截
JavaScript对dom生成的影响
当HTML解析器遇到<script>标签时,渲染引擎判断出这是一段脚本,此时HTML解析器会停止对DOM的解析,因为段脚本里的代码可能会对已经生成的DOM树进行操作。所以渲染引擎会先执行完脚本代码再继续启动HTML解析器进行DOM解析。也就是说当有JavaScript在文档中时,DOM生成会被阻塞。同时若一个JavaScript脚本代码中对DOM进行了操作,但它操作的DOM位于该段代码的<script>标签之后那么这行代码就会执行失败,因为此时需要被操作的DOM并没有渲染出来。这就是为什么通常我们将JavaScript代码放在html文档最后的原因。<script>标签放在html文档的头部,当<script>中代码较多所需执行时间很长时我们的页面就会出现白屏。
当我们使用外部链接来加载<script>代码时,浏览器需要先下载这段代码,而下载过程同样会阻塞DOM解析,此时如果源js文件站点网络较差就会导致长时间白屏。
为了解决这个问题Chrome浏览器做了许多优化,主要的就是预解析操作。当渲染引擎接收到字节流以后会开启一个预解析线程用于分析html文件中包含的JavaScript、Css等相关文件,解析到了会提前下载这些文件以防止阻塞
上面我们知道JavaScript脚本会阻塞DOM的生成,对此我们也有可以采用一些方法来规避,例如当javascript代码中没有DOM操作相关的代码时,就可以将该JavaScript脚本设置为异步加载,或者使用CDN加速、代码压缩等方法。
使用async异步加载代码
<script async type="text/javascript" src="foo.js"></script>使用defer异步加载代码
<script defer type="text/javascript" src="foo.js"></script>虽然async和defer都是异步加载javascript文件,但是async加载完js文件后会立即执行里面的代码而defer则会在DOMContentLoaded事件前执行
在页面的JavaScript代码中我们可能并不会增删DOM但会修改DOM的样式,操作CSSOM。如果js代码里操作了外部的CSS那么浏览器同样要等待外部的CSS文件下载完成并解析生成CSSOM对象之后才能执行JavaScript脚本。也就是说单纯的外部css文件并不会阻塞DOM渲染,但若是js代码中操作了外部css文件则该css文件就会间接导致DOM渲染被阻塞

当HTML解析器发现需要css、js外部文件时,浏览器会同时发起请求进程,也就是说请求css和js文件是并行的,所以在我们计算加载时间时仅需计算最大的那个文件所需传输时长即可
首页白屏优化
通过上面的分析我们知道一般情况下网页性能瓶颈主要体现在css下载和js文件下载和代码执行中,所以想要缩短白屏时长我们可以采取以下策略:
- 通过内联
css和js来消除文件下载时导致的进程阻塞 - 在不适合内联
css、js的情况下尽量减小文件大小,例如webpack的Tree Shaking - 对于未操作
DOM的js文件用async或defer异步加载 - 对于大的
css文件使用媒体查询将其拆分为多个css文件,需要用的时候再加载相关css文件
页面渲染全过程
- 渲染进程将
html文档转换为渲染引擎能够识别的DOM树结构 - 渲染引擎将
css样式表转换为可以理解的styleSheets,计算出DOM节点的样式生成CSSOM - 创建布局树,并计算元素的分布信息
- 对布局树进行分层并生成分层树
- 为每个图层生成绘制列表,并将其提交到合成线程
- 合成线程将图层分成图块,并在光栅化线程池中将图块转换成位图
- 合成线程发送绘制图块命令
DrawQuad给浏览器进程 - 浏览器进程根据
DrawQuad消息生成页面,并显示到屏幕上